

Before jumping into this detail of the topic I would like to make the definition of schema and Work schema with respect to ODI Topology clear and i.e
SCHEMA – Schema where ODI inserts and updates the target tables.
WORK_SCHEMA – Schema where all the ODI Temporary table ( C$_,I$_ etc ) are created and dropped by ODI.
Work Schema is an important part of the ODI Architecture. As you all know ODI create Temporary tables, for its loading, integration and transformation from the various source to the target, such as C$_, I$_ etc. These temporary tables can create a lot of junks and ugliness in your target table in the long end.
The best solution is creation of separate Database schema or user called “WORK_SCHEMA” or ” TEMP ” or “ODI_TEMP” whatever you wish name as per your environment , but the most important part is how you use it .
I very strongly recommend the usage of using this TEMP as ‘ Schema (work schema ) ‘ option in Physical schema for all the technologies. The result and the impact of this is whenever ODI create temporary tables ( C$_, I$_ etc ), you can drop or clean the space of this schema as any time, thus avoiding clutter or temporary ODI tables in the target schema.
Let’s see this option diagrammatically.
Option 1 – Having the Schema and the Work Schema in Topology same.
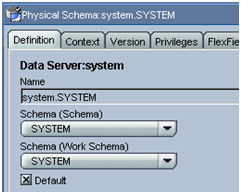
In such a scenario, ODI will create Temp tables (C$_, I$_ ) in the same schema , the result as you can see lots of junk . Would you love to have such scenario in your Production box?
|
SYSTEM (Schema) |
| EMPLOYEE ( Table) SALES ( Table) |
| C$_employee I$_employee C$_sales I$_sales |
Option 2 – Having the Schema and the Work Schema in Topology different.
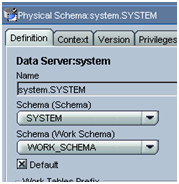
In such a scenario, ODI will create Temp tables (C$_, I$_) in the different schema, the result as you can see no junks and DBA can drop this WORK_SCHEMA ODI tables at regular interval.
|
SYSTEM (Schema) |
| EMPLOYEE ( Table) SALES ( Table) |
|
WORK_SCHEMA (Schema) |
| C$_employee I$_employee C$_sales I$_sales |
I know what you all are thinking, isn’t ODI drops all the temporary tables, well the answer is yes but how many times you have created interfaces that you would create just for
Testing purpose
or failed interface still not going till Drop table option
or some time due to some error it fails to drop the table ,
The result presence of these tables permanently in Database unless dropped manually.
I have seen companies using such schema with the option “Staging are different from the target” which is not a good practice of using such schema, as you generally developer would forget to use this option. Moreover, its best and easy to implement in topology rather than to use at 100s of interface created and still the Knowledge Modules creates the Temporary schema in the work schema before doing the Insert and Update.
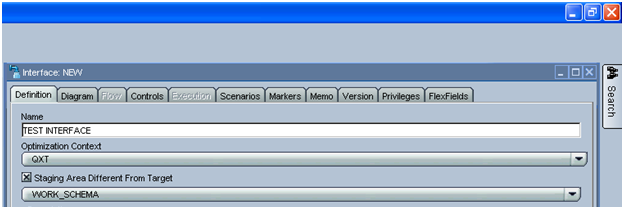
Second advantage of defining in the topology is that, mostly we define the temporary table in the work schema so we would create all the temporary tables in work Schema.
This option can be considered an important aspect in ODI Best Practices.
Pingback: Database Schema to hold ODI temporary objects – Oracle Data Integrator